On June 16, Z.ai (formerly Zhipu AI) released GLM-5.2, an open-weights model with 753 billion parameters built for one thing: long-horizon, autonomous engineering work. For businesses there are two stories here at once. GLM-5.2 beats GPT-5.5 on several coding benchmarks, and its API costs roughly six times less. Every number below comes from VentureBeat's report and Z.ai's own data.
At Gless we pick the model behind a client's system every week, so a release like this isn't a news headline to us. It's a working question: what's worth putting into production now. Let's go through it honestly. Where GLM-5.2 is genuinely stronger, where it's behind, and whether you should change anything today.
What Z.ai actually shipped
GLM-5.2 is already live on Hugging Face, through the Z.ai API, and across more than 20 third-party coding environments. The context window is a stable one million tokens, and subscriptions start at $12.60 a month.
Under the hood sits an architectural trick called IndexShare: one indexer is reused across every four sparse-attention layers. At the full one-million-token context, that single change cuts per-token compute by 2.9x. There's also an upgraded Multi-Token Prediction layer for speculative decoding, which raises accepted token length by up to 20% at inference.
One more detail for anyone who watches the inference bill: switchable "thinking modes." Max pushes peak intelligence but burns around 85,000 output tokens per task. High gives up only a few points and roughly halves that output, which is a useful lever when latency matters.
GLM-5.2 benchmarks: where it beats GPT-5.5, and where it doesn't
Short version: GLM-5.2 is strongest in agentic and long-horizon engineering tasks, the kind where the model drives a job across several steps instead of answering in one shot.
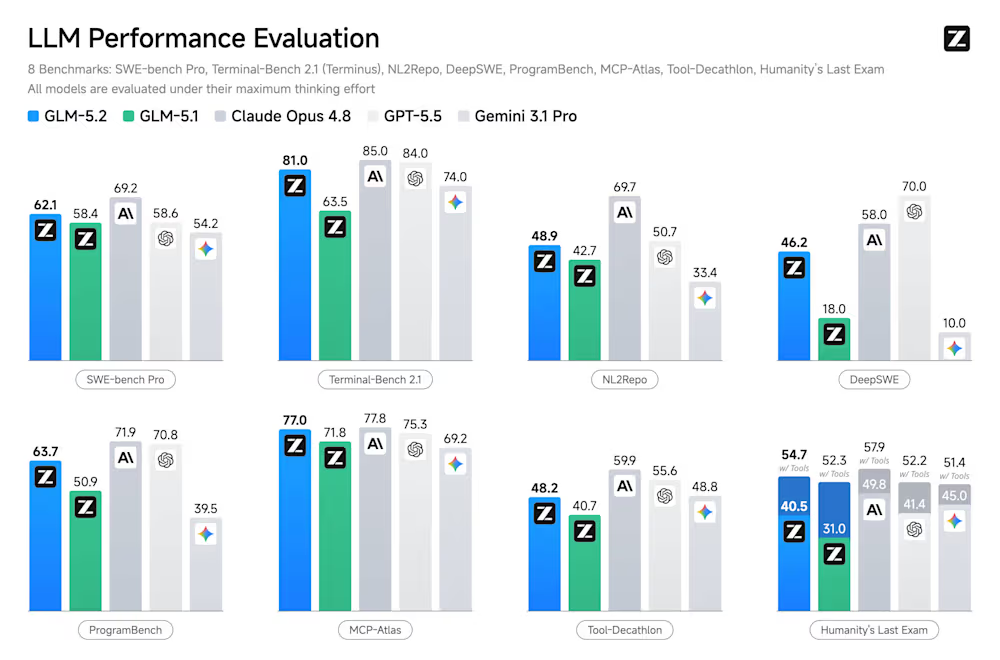
On SWE-bench Pro it scored 62.1 against GPT-5.5's 58.6, and it even beat its own predecessor, GLM-5.1 (58.4). On FrontierSWE, which tests whether a model can finish a long task, it hit 74.4% versus GPT-5.5's 72.6%, nearly tying Claude Opus 4.8 (75.1%). PostTrainBench is where the gap is widest: 34.3% against 25.0%.
The honest weak spot is Terminal-Bench 2.1, where GLM-5.2 trails at 81.0 against 84–85 for GPT-5.5 and Opus. Even there it has a footnote in its favor: it's the first open-weights model to cross 80% on that test, and it clearly outscores Google's Gemini 3.1 Pro (74.0). On the crowdsourced Design Arena benchmark, GLM-5.2 took first place with an ELO of 1360.
So the picture, minus the hype: level with or above the top proprietary models on long and agentic work, and still a step behind on raw terminal tasks.
Price is where this gets decided
The most consequential part of the release for a business isn't the scores, it's the bill. Look at the output row, since that's what costs the most.
| Model | Input / 1M | Output / 1M | Total |
|---|---|---|---|
| GLM-5.2 | $1.40 | $4.40 | $5.80 |
| Claude Opus 4.8 | $5.00 | $25.00 | $30.00 |
| GPT-5.5 | $5.00 | $30.00 | $35.00 |
GLM-5.2 charges $1.40 per million input tokens and $4.40 per million output. GPT-5.5's output alone runs $30, so the "6x cheaper" in the headline is just arithmetic, not marketing. For long-context work there's also cached input at $0.26 per million.
If you'd rather skip the raw API, the GLM Coding Plan tiers are Lite at $12.60 a month, Pro at $50.40, and Max at $112. All of them work out of the box with Claude Code, Cline, Kilo Code, Crush, and other harnesses.
AI commentator @scaling01 put the pricing gap bluntly, arguing the proprietary labs are sitting on "90%+ margins." Sharp phrasing, but the table above mostly backs it up.
The MIT license and control over your own stack
The most underrated part of the release is the license. GLM-5.2's weights ship under MIT, which makes it "pure open" with no strings. You download the model from Hugging Face, fine-tune it, run it on your own hardware or VM, and pay only for compute. No royalties, no "acceptable use" policy, no lock-in to a single vendor.
Here's why that suddenly matters this week. The US administration issued an export-control directive barring foreign nationals from using Anthropic's newest model, and Anthropic responded by pulling the affected models offline for everyone. For a business outside the US, the signal is blunt: access to a top proprietary model can be cut for political reasons, not technical ones. Open weights remove that risk, because the model already sits on your disk and nobody can take it back.
We're not arguing for "open source at any cost." But being able to run a frontier-level model on your own infrastructure isn't about saving a few dollars on tokens. It's about not getting switched off at the wrong moment.
When to go open-weights, and when not to
Pretty benchmarks and real production are two different stories, so let's get practical.
The token price is almost never the deciding factor in the budget. When we cost out an AI system for a client, tokens are often the smaller line. The infrastructure to self-host a 753B model, the engineers who stand it up and keep it healthy, a real eval, quality monitoring: that's where the money goes. "Free MIT weights" and "cheap solution" are not the same thing.
Where open-weights genuinely wins:
- sensitive data you can't send through someone else's API;
- sovereignty requirements or air-gapped environments;
- predictable load that justifies owning the hardware;
- a need to fine-tune the model for a narrow domain.
Where a proprietary model is still the calmer choice: small teams with no DevOps for GPUs; terminal-heavy tasks, where Opus and GPT-5.5 are still ahead; and projects where grabbing a ready endpoint and ignoring infrastructure is simply faster.
On most projects we stay platform-neutral: we design the architecture around the task, not around one model, and we leave room to swap providers. GLM-5.2 widens that optionality a lot. "An open model at GPT-5.5 level" used to sound like a contradiction; now it's a real production option. We've already written about why AI doesn't replace engineers, and this release shows it plainly: an open model doesn't reduce the need for people, it shifts that need toward infrastructure and architecture.
If you want AI implementation for a specific task, helping you choose between open-weights and proprietary for your case, rather than by fashion, is exactly what we do.
FAQ
What is GLM-5.2?
An open-weights language model with 753 billion parameters from Chinese startup Z.ai (formerly Zhipu AI), released on June 16, 2026. It's built for long-horizon autonomous coding tasks and is available on Hugging Face and via API under an MIT license.
Is GLM-5.2 really cheaper than GPT-5.5?
On API pricing, yes, by a lot. GLM-5.2's output costs $4.40 per million tokens against GPT-5.5's $30, roughly six to seven times less. The full comparison is in the table above.
Can I self-host GLM-5.2?
Yes. The MIT license lets you download the weights, fine-tune them, and run the model locally with no royalties or regional limits, paying only for compute. Just budget for it: a 753B model needs serious GPU infrastructure and people to run it.
Does open-weights mean lower quality?
Not anymore. On several coding and agentic benchmarks GLM-5.2 matches or beats GPT-5.5 and Claude Opus 4.8. Proprietary models are still slightly ahead on pure terminal work.
Should my business switch from GPT-5.5 to GLM-5.2?
It depends on the task. If data control, sovereignty, or predictable self-hosted load matter to you, it's worth testing at least. If you're a small team with no GPU DevOps, a proprietary API is often simpler. We work through these forks in our consultations.
If you want to figure out which of these fits your task, get in touch and we'll look at your specific case.